据英国《自然·通讯》杂志10日发表的一项最新成果,美国北卡罗来纳州立大学研究人员将DNA数据存储方面的长期挑战转化为一种实用工具——为用户提供存储数据文件的“预览”,例如图像文件的缩略图版本。这使得整个DNA存储系统数据效率大为提高,同时更具兼容性。
全球的数据量不断增加,传统的存储架构,如硬盘和磁带,越来越难以跟上数据存储的需要。随着这些装置逐渐达到存储极限,DNA被当作一种长期存储方案提出来,这是一项非常有吸引力的技术,因为只需要一个小片段就可以存储大量数据,信息可以长时间保持,又非常节能。
但是科学家们一直还无法实现对DNA文件中数据的“预览”——如果你想知道文件是什么,那你必须“打开”整个文件。
据研究人员介绍,为了识别和提取指定文件,大多数系统使用聚合酶链反应(PCR)。具体来说,使用与相应引物结合序列匹配的小型DNA引物来识别包含所需文件的DNA链。然后系统使用PCR制作大量相关DNA链的副本,再对整个样本进行测序。该过程会复制大量目标DNA链,但目标链的信号比样本的其余部分更强,从而可以识别目标DNA序列并读取文件。然而,DNA数据存储研究人员面临的一个巨大挑战就是,如果两个或多个文件具有相似的文件名,PCR将无意中复制多个数据文件的片段。因此,用户必须为文件指定非常不同的名称,以避免产生数据混乱。
此次,北卡罗来纳州立大学研究团队开发的这种技术,利用相似的文件名可以打开整个文件或该文件的特定子集。这是通过在命名文件和文件的给定子集时使用特定的命名约定来实现的,研究人员可以PCR过程的几个参数,温度、样本中DNA的浓度以及样本中试剂的类型和浓度,来选择是“打开”整个文件还是只“打开”其“预览”版本。
这一新技术的优势体现在效率和费用两大方面,该论文的第一作者、研究人员凯尔·托梅克表示,“如果你不确定哪个文件包含你想要的数据,也不必对所有潜在文件中的所有DNA进行测序,相反,还可以对DNA文件的更小部分进行测序以作为预览”。
研究团队成员表示,这一技术已展示了与其他文件类型广泛兼容的能力,目前他们正在寻找行业合作伙伴来帮助探索该技术的商业可行性。(记者张梦然)
 全球观察:端午节期间日均132.1万人次出入境 较去年增长约2.3倍 据国家移民管理局25日消息,2023年端午节期间全国边检机关共查验出入境
全球观察:端午节期间日均132.1万人次出入境 较去年增长约2.3倍 据国家移民管理局25日消息,2023年端午节期间全国边检机关共查验出入境
 汽车博主发表贬损极狐汽车言论 极狐要求永久删除 近日,北汽极狐公司针对知名汽车博主袁启聪在抖音和微博发布的涉及极狐
汽车博主发表贬损极狐汽车言论 极狐要求永久删除 近日,北汽极狐公司针对知名汽车博主袁启聪在抖音和微博发布的涉及极狐  天天视点!极限 极限有高有低……心理极限极高的人可能身体会先到极限而出问题。身体极
天天视点!极限 极限有高有低……心理极限极高的人可能身体会先到极限而出问题。身体极  世界热推荐:观众齐喊“开空调”!梁静茹沈阳演唱会遭遇尴尬一幕 近期高温预警,再加上演出现场人员爆满,昨天是满场,估计昨天观看演唱
世界热推荐:观众齐喊“开空调”!梁静茹沈阳演唱会遭遇尴尬一幕 近期高温预警,再加上演出现场人员爆满,昨天是满场,估计昨天观看演唱 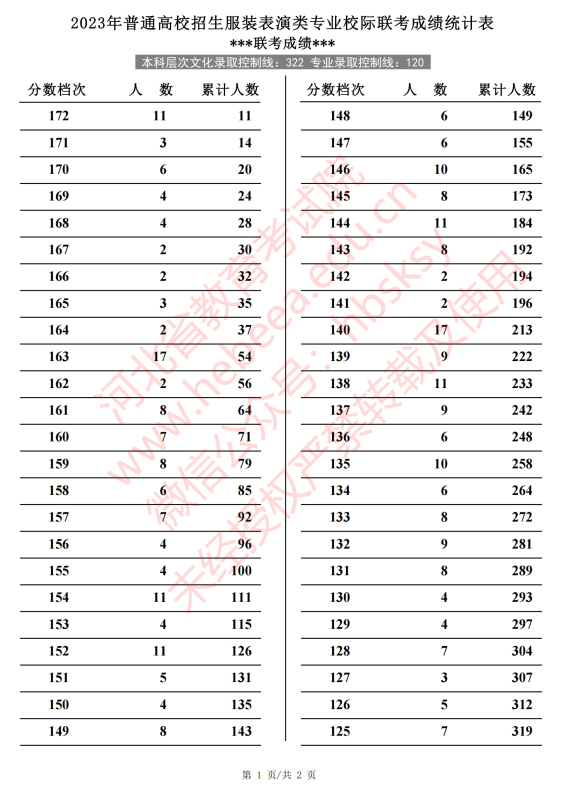 每日快看:2023年河北省普通高校招生服装表演类专业校际联考成绩统计表(专业成绩·综合成绩) 最新高考资讯、高考政策、考前准备、志愿填报、录取分数线等高考时间线
每日快看:2023年河北省普通高校招生服装表演类专业校际联考成绩统计表(专业成绩·综合成绩) 最新高考资讯、高考政策、考前准备、志愿填报、录取分数线等高考时间线  海口江东新区将建香港玉玲珑珠宝产业园 近日,记者从海口江东新区管理局获悉,位于海口江东新区离岸创新创业组
海口江东新区将建香港玉玲珑珠宝产业园 近日,记者从海口江东新区管理局获悉,位于海口江东新区离岸创新创业组





